SparkPlug employs Spark and HDFS to supercharge ML app performance through distributed computing. Spark and HDFS clusters, however, can be tricky to configure and time-consuming to the uninitiated engineer. Furthermore, to tune Spark applications, we need a distributed test environment akin to the final operational environment posing a significant logistic and economic challenge to developers. SparkPlug remedies these problems through containerization.
The SparkPlug deployment strategy containerizes the entirety of the underlying distributed infrastructure so that SparkPlug apps are ready to deploy out of the box with zero configuration. Let’s take a detailed look at this strategy now.
Deployment Strategy Overview

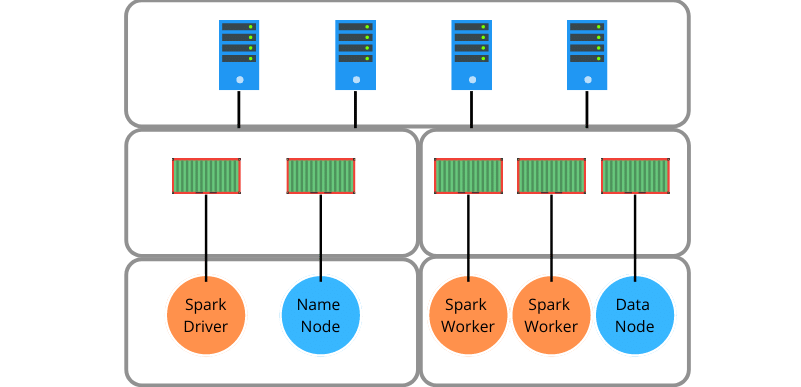
From the bottom, each component of the HDFS and Spark clusters are encapsulated into a unique container. The blue nodes relate to HDFS well the orange nodes are part of Spark. Spark is deployed in standalone mode using its built-in cluster manager rather than Yarn (Hadoop). This approach offers a clean and simple architecture and works great for apps like GeoPredict, which can run entirely in memory. If HDFS needs to be used more extensively in the regular course of operation, Spark should be deployed on Hadoop to take advantage of HDFS data locality. Stay tuned for SparkPlug 2.0!
SparkPlug apps are designed for batch processing. Therefore, the conductor infrastructure, which contains the web app and the scheduler, is static, but the followers are scalable. There is always exactly one of each type of conductor container and at least one of each type of follower in practice. If an application needs more data processing capability, we provision Spark Workers, and if it needs more storage, we add Data Nodes.
The containers are all defined programmatically using Docker Compose. Most containers are prebuilt and automatically retrieved from the Docker registry upon launch from the CLI. The SparkDriver container, however, needs to be rebuilt every time the underlying user app changes. Additional SparkWorkers need to be rebuilt when tuning to change executor and core count parameters. The SparkPlug CLI takes care of these compilation tasks.
Deploying SparkPlug In the Cloud
Docker Swarm manages container orchestration over physical infrastructure. The SparkPlug API offers some abstraction for Swarm; however, the program will need to be installed manually on the physical infrastructure. SparkPlug itself, however, only needs to be installed on a single machine. I deployed GeoPredict on SparkPlug using Amazon EC2 instances as the physical infrastructure. To do this, I installed GeoPredict and Swarm on one instance and installed just Swarm on another one. Then I made AMI images of both the conductor and follower instances. Using these images effectively automates setup for the EC2 platform. You deploy a single AMI to an instance as the conductor and provision instances with the follower AMI as you horizontally scale. The framework includes these images to make getting started with AWS a breeze.
General Benefits
So why do we go to all the trouble of deploying the entire SparkPlug infrastructure through containers?
- Easy initial setup- everything is ready to go out of the box
- Robustness- automatically deploy a new container if one goes down
- Quick scaling- immediately deploy new containers to newly added physical infrastructure
DevOps
One more thing. Containers empower DevOps for distributed computing! Access to physical resources is expensive. It doesn’t make sense to develop on an entire physical compute cluster; it is much more economical to use a laptop. We can capitalize on containerization to simulate a physical cluster well only using a single machine. The underlying Spark and HDFS clusters are entirely agnostic to the containers running on a single device or spread across a physical cluster. The entire configuration, most critically networking, will work the same way at the environment layer, no matter the physical layer’s configuration.
Another fantastic property of containers is that we can dynamically allocate them resources (cores and memory) and effectively adapt to different compute topologies. The simplest topology is when every machine is identical. In this case, the ideal solution is to provision one container per physical machine. When our physical nodes are not of uniform power, however, this no longer makes sense. Consider this physical cluster:

We have three different physical nodes with varying amounts of resources. If we tune our SparkWorker for the least performant node and then deploy one container per node, we do not fully utilize our resources. We can resolve this by simply deploying more containers to the more powerful nodes until we achieve full resource utilization. Because we only must tune the SparkWorker once (setting the # of executors and cores per executor), we simplify development. Additionally, it helps bridge the Dev and Ops gap because, in most cases, personal desktops are more powerful than commodity hardware, so we can have multiple SparkWorker containers running on our development machines, tuned the same way as they would be at scale.
Conclusion
Hopefully, I have managed to convince you of the splendor of a containerized distributed computing infrastructure. Next time we will talk about the DevOps tooling that empowers everything we have talked about thus far.