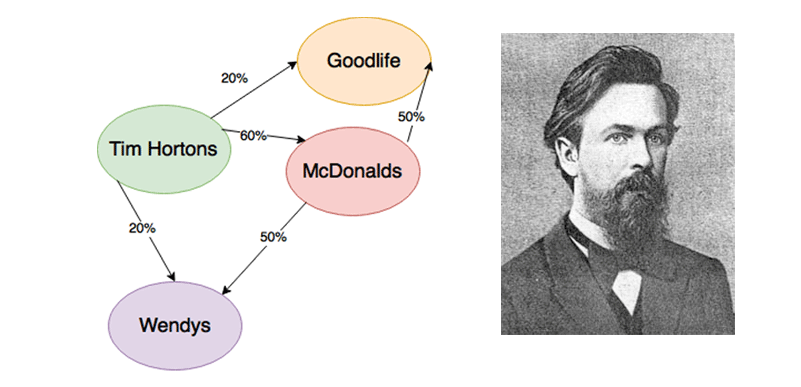
The N-MMC we have developed thus far are excellent tools for the general problem of next place prediction. Now we must focus on adapting the model to accommodate the complications of trip prediction.
Trip Separation
The structure of the data poses the first complication. So far we have assumed that all Visits in a MobilityTrace are sequential, but in reality, they are not because Visits to private locations have been removed. Non-sequential Visits results in false inferences when training our N-MMC. To illustrate this point consider training a 2-MMC using the following MobilityTrace:
Bed Bath Beyond -> 7:00
McDonald’s -> 7:30
SplashWorld -> 20:00
There are two bi-visits in this MobilityTrace: “Bed Bath Beyond McDonald’s” and “McDonald’s SplashWorld” each with a single occurrence. Thus, if given the context McDonald’s we would predict SplashWorld as the next POI. Looking at the timestamps, we notice that McDonalds and SplashWorld are many hours apart. It is reasonable to assume that the user didn’t just stay at McDonald’s till 20:00 and likely visited other personal POIs in between McDonald’s and SplashWorld that were removed. These Visits are not sequential, yet we treat them as if they are. If we don’t rectify this issue, we might make the false inference that people tend to eat right before they swim which for many people is not the case.
Another way to think about this MobilityTrace is that it is composed of two separate trips. The first trip in the morning and the second at night. To avoid false inferences, we must make sure that all visits in an n-visit are from the same trip. Luckily it is relatively straightforward to create these groupings by merely looking at the amount of time between two Visits.
For two “sequential” Visits in a MobilityTrace let the first Visit occur at time Ta and the second Visit with time Tb.
Let Te be a hyperparameter defining a time threshold between two trips
If |Tb-Ta| > Te punctuate MobilityTrace with End of Trip (EoT) after Ta
How do we figure out the correct hypermeter Te to prevent false inferences? The ideal solution would be to optimize Te using a duplicate MobilityTrace containing EoT markers. Without this labelled MobilityTrace we don’t have ground truth, and the best we can do is make an educated guess- somewhere around three to four hours should be ideal.
Selecting the Right (N)-MMC
Now that we have split our MobilityTrace into trips, we move on to choosing the correct amount of context. The MobilityTrace provided by my partner was captured over three months, and the number of Visits recorded for each user varied significantly meaning that the correct N might differ depending on the user.
My intuition was that the N value appropriate for trip prediction would be in the neighbourhood of the N value for the general mobility problem (N=2). The big difference between general mobility and trip prediction is that long n-visits are less frequent because they get cut off when trips end, thus a smaller N value might be better because n-visits of a high order would mean many unseen contexts.
I moved forward and conducted an empirical analysis, comparing N=1 to N=5 MMC for every user. The data showed that for most users the 2-MMC model was the best. For the most active users (the top 10%), however, a 3-MMC was better. If we had six months of data would this change anything? The answer is not clear because while we would have more Visits, perhaps the prior Visits would be outdated. It may be the case that 3-MMC only works well for users that go on long shopping trips.
Smoothing
Maximum likelihood estimation is an adequate technique if all we care about is trying to make the best guess possible with the data we have. A great deal of value, however, comes from being able to present a probability distribution for every prediction so that the data is more actionable based on the tolerances of error for the desired application. For example, if GeoPredict is being used to send emergency alert messages warning people to steer clear of a specific POI, any POI in the distribution with a 10% likelihood or higher might be considered actionable. If GeoPredict is used for targeted advertising, then perhaps you might only want to push ads when there is a >60% chance of the next Visit being to a particular POI.
If we care about the accuracy of the distribution, then we must adjust for the unseen events in the probability space (the unseen n-visits). As N increases the number of possible paths we can take through our MMC explodes by #POIn. As these paths (n-visits) increase the data set becomes sparer. We can define the total number of possible POIs as the number of POIs in a geographic region available in the Google Maps database. There are several methods for smoothing our distributions to resolve the sparsity problem, but perhaps the best is an adapted version of Good-Turing frequency estimation which works by borrowing some of the probability space from the seen events and allocating it to the unseen events. This technique is commonly employed in NLP for similar purposes.
Multiple Models
A 3-MMC inherently contains a 2-MMC and 1-MMC inside of it thus we only need to store a 3-MMC (tri-visits) and can derive the counts of bi-visits and uni-visits. However, this process is computationally expensive, and we are looking to maximize speed to achieve near real-time predictions it is best to make a time-space tradeoff by generating hash tables to store the count of all n-visits from n=1 to the desired N. While to make predictions with a 3-MMC we only actually need tri-visits and bi-visits it is prudent to keep uni-visits because it allows us the flexibility to use a lower order N model if we don’t have enough context so that we can always make some educated prediction.
Expanded Context (Day of The Week)
So far we have constructed a model in which the state is represented only by physical and semantic location. What about time? Can we use temporal context to aid in predictions? To realize this expanded context I built 7 N-MMC as opposed to one in which each N-MMC was trained using trips from a particular day of the week. The idea here is that many commercial offers and promotions occur on a specific day of the week and that may be a determent of consumer shopping habits.
I tested my day of the week N-MMCs by considering the day of the week at prediction time and making the prediction only using the associated N-MMC. Unfourtantly the results were worse than just using a single N-MMC. There just wasn’t enough data to make this approach work because so many n-visits were unseen and thus the system kept reverting down to uni-MMC to make predictions. Perhaps with more Visits (6 month collection period), this would be worth another shot.
Training/Operation Phase Notes
During training, we can think of each trip as a MobilityTrace which we train separately on the same table of counts. At the start of the trip, we have no context, so we can only count uni-visits and then as we get more context we count bigger n-visits up to the (N) parameter of the selected model (N=2 or N=3).
When making predictions (operation phase) we receive Visits on a continual basis as they occur. We cannot know if the next Visit we will receive will be on a different trip thus we always make a prediction as soon as a Visit is received. We do need to consider the case where N > 2 as we can apply threshold Te between the context to ensure it is from the same trip. Remember that if the time gap is over the threshold and we have to through away the first piece of context we can revert to a 2-MMC model.
During the prediction phase, we also must make sure that the timestamp on the most recent Visit we receive is close to the current system time. If there is too much of a delay in receiving the Visit, it is likely the user always transitioned.
All the visits we capture during the operation phase can be saved so we can update the model’s counts in the future.
Conclusion
So there we have it- a novel recommender system to address the problem of shopping trip prediction. Of course, as with any data solution, there is lots of room for improvement particularly in the area of metric development and testing. Overall, however, GeoPredict performs similarly to recommender systems for general mobility- which is an excellent result. To see how we scale GeoPredict to handle big data read my series on SparkPlug.