This series details the development of a novel machine learning solution called GeoPredict. I designed GeoPredict with the intent of leveraging large-scale mobility data in a commercially viable manner.
The first step towards the development of GeoPredict was gaining a solid understanding of the problem domain-the data. The data provided by my industry partner was not just raw mobility data but a richer set of contextual and semantic information. Let us try to unpack the structure of this data.
Understanding the Data
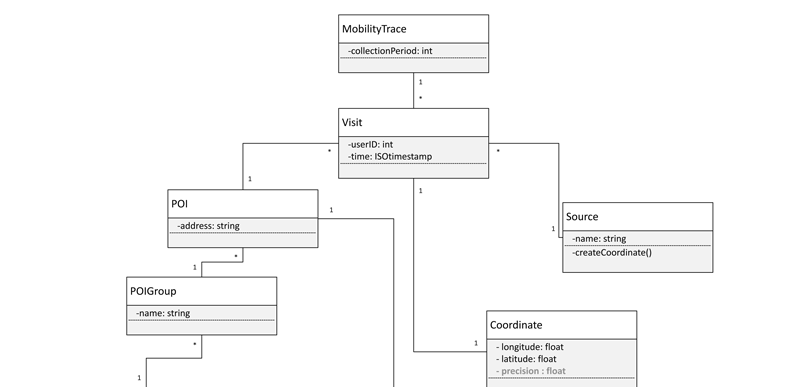
We call a set of data a MobilityTrace and a discrete data point a Visit. My partner collected the provided MobilityTrace from their user base (millions of users) over three months.

A Visit is created when a Source captures a new Coordinate. A Coordinate contains the position of the Source (longitude and latitude) and the precision of this measurement.
Precision is the attribute of a Coordinate accounting for the uncertainty in the position calculation. It is the radius of the circle surrounding the given position. Each Source uses different methods for determining position. These include but are not limited to WiFi triangulation, cellular triangulation, and GPS. Each of these methods has different ranges of baseline precision that vary due to environmental factors.
A Source itself is the specific platform upon which my partner’s application runs. Sources include web browsers, mobile operating systems, and mobile browsers. As people tend to keep their cell phones on their person, Visits collected from mobile Sources are vital because they serve as a better proxy for human mobility than static Sources such as a desktop web browser.
A userID is an attribute assigned to each Visit to enable analysis on a per-user basis. A user could have multiple ids if they are not logged in across Sources. For privacy, my partner opted not to tie each Visit to a complete UserProfile but only the numeric userID.
The most significant preprocessing step on the provided MobilityTrace was tagging each Visit with a commercial POI (point of interest). Each POI is an individual location belonging to a POIGroup. For example, Starbucks is a POIGroup, but the Starbucks with the address 1 Bayside Drive is a POI.
POI tagging was accomplished using a commercial database licensed by my partner. My partner removed all Visits that could not be tagged. This purge is significant in that any value to be had from the MobilityTrace would relate to shopping trips as opposed to general mobility.
Unsupervised Approach
Once I fully understood the nature of the data, I turned my attention to refining my goal: what type of value could my solution deliver? My first intuition was to see if I could uncover any hidden structural value with an unsupervised learning approach. I started with just one feature, using the distance between the Coordinates to cluster the Visits with k-means. Upon inspection of the resulting clusters, I realized that I had stumbled upon a method of discovering POIs. At a low resolution, the group labels represented entire geographic regions (cities and towns), but at a higher resolution, the labels signified POIs.
By utilizing a third-party database, my partner was already able to label these clusters. I wondered, however, what would happen as new POIs emerged. Would my partner depend on their data provider to provide timely updates? Was there a way I could build a system to discover and label new POIs to break this dependence? I started brainstorming some potential solutions.
The first approach that came to mind was to match the cluster coordinates to an address on a city map and then build a web crawler to find mentions of the address on social media with the intention of extracting a POI name. Another potential solution would be to collect photos geotagged with cluster’s coordinates and use computer vision techniques to obtain the names of the storefronts in these pictures. I reckoned Google might use a similar approach with the vast amount of Street View imagery. Although both these techniques were of interest to me from an academic standpoint, they were outside my operating parameters in that they would require additional data (city maps, user photos) and thus not be commercially viable to my partner.
I continued by trying to cluster a higher dimensional set of features considering time, distance and category. I used principal component analysis to produce a unified distance metric for input into k-means. Upon inspection of the results, I was unable to draw any useful conclusions. I decided it was time to move on.
Supervised Approach: Recommender Systems
Frustrated with my lack of progress, I resolved to binge-watch an entire season of Stranger Things on Netflix. Upon completion of the season, I was left impressed. Not just by the wonderfully nostalgic world of Hawkins but with Netflix’s suggestion for what I might watch next. Netflix aptly combined the context of Stranger Things with my viewing habits to come up with a strong set of candidates. It was the idea of context that intrigued me. If I liked Stranger Things, then I would probably like Aliens too. Could I use the context of a recent Visit to predict the next one?
What makes the ability to predict a user’s next Visit valuable? Suppose a user, Alice, is currently at Goodlife Fitness, and we have a recommender system to predict that she will go to McDonald’s next. Other businesses in the Food & Beverage space could participate in a real-time bid for the ability to market to Alice right before she makes her decision. The confidence of the recommendation could help the bidders tune their bids. A second potential application is an emergency alert system. Let us say that the police just evacuated the McDonalds Alice was likely to visit; an alert could be sent to Alice warning her to steer clear. The applications of these recommendations go on and on- the value is obvious. Additionally, the system seemed feasible, given the MobilityTrace I was working with and my time constraints. Thus it was clear- my goal would be to build a near real-time recommender system for shopping trip forecasting.